دادههای کلان چیست؟
دادههای کلان ترکیبی از دادههای ساختیافته، نیمهساختیافته و غیرساختیافته است که سازمانها برای جمعآوری، تحلیل و استخراج اطلاعات و بینشها از آن استفاده میکنند. این دادهها در پروژههای یادگیری ماشین(Machine Learning) ، مدل سازی پیشبینی(predictive modeling) و سایر کاربردهای تحلیل پیشرفته به کار میروند.
سیستمهایی که دادههای کلان را پردازش و ذخیره میکنند، به جزء مشترکی از معماریهای مدیریت داده در سازمانها تبدیل شدهاند. این سیستمها با ابزارهایی که از کاربردهای تحلیل دادههای کلان پشتیبانی میکنند، ترکیب میشوند. دادههای کلان معمولاً با سه ویژگی V مشخص میشوند:
حجم بالای داده در بسیاری از محیطها(Volume) .
تنوع وسیع انواع دادهها که بهطور مکرر در سیستمهای دادههای کلان ذخیره میشوند(Variety) .
سرعت بالای تولید، جمعآوری و پردازش دادهها(Velocity) .
اگرچه دادههای کلان معادل با هیچ حجم خاصی از داده نیستند، پیادهسازیهای دادههای کلان معمولاً شامل ترابایتها، پتابایتها و حتی اگزابایتها از نقاط دادهای است که بهمرور زمان ایجاد و جمعآوری شدهاند.
چرا دادههای کلان اهمیت دارند و چگونه از آنها استفاده میشود؟
شرکتها از دادههای کلان در سیستمهای خود برای بهبود کارایی عملیاتی، ارائه خدمات بهتر به مشتریان، ایجاد کمپینهای بازاریابی شخصی سازی شده و انجام اقدامات دیگری که میتواند درآمد و سود را افزایش دهد، استفاده میکنند. کسبوکارهایی که بهطور مؤثر از دادههای کلان استفاده میکنند، نسبت به آنهایی که این کار را نمیکنند، مزیت رقابتی بالقوهای دارند زیرا قادرند تصمیمات تجاری سریع تر و آگاهانه تری بگیرند.
به عنوان مثال، دادههای کلان بینشهای ارزشمندی درباره مشتریان ارائه میدهند که شرکتها میتوانند از آنها برای بهبود بازاریابی، تبلیغات و ترویجها استفاده کنند تا تعامل و نرخ تبدیل مشتری را افزایش دهند. هم دادههای تاریخی و هم دادههای زمان واقعی میتوانند برای ارزیابی ترجیحات در حال تحول مصرف کنندگان یا خریداران شرکتی تحلیل شوند و به کسب وکارها این امکان را میدهند که به خواستهها و نیازهای مشتریان پاسخگوتر شوند.
پژوهشگران پزشکی از دادههای کلان برای شناسایی علائم بیماری و عوامل خطر استفاده میکنند. پزشکان از آن برای کمک به تشخیص بیماریها و شرایط پزشکی در بیماران استفاده میکنند. علاوه بر این، ترکیبی از دادههای سوابق سلامت الکترونیکی، سایتهای رسانههای اجتماعی، وب و منابع دیگر به سازمانهای بهداشتی و نهادهای دولتی اطلاعات به روز درباره تهدیدات و شیوع بیماریهای عفونی ارائه میدهد.
در اینجا چند مثال دیگر از اینکه چگونه سازمانها در صنایع مختلف از دادههای کلان استفاده میکنند، آورده شده است:
دادههای کلان به شرکتهای نفت و گاز کمک میکند تا مکانهای بالقوه حفاری را شناسایی کرده و عملیات خطوط لوله را نظارت کنند. به همین ترتیب، شرکتهای خدمات عمومی از آن برای پیگیری شبکههای برق استفاده میکنند.
شرکتهای خدمات مالی از سیستمهای دادههای کلان برای مدیریت ریسک و تحلیل لحظهای دادههای بازار استفاده میکنند.
تولیدکنندگان و شرکتهای حمل و نقل به دادههای کلان برای مدیریت زنجیره تأمین و بهینهسازی مسیرهای تحویل وابسته هستند.
سازمانهای دولتی از دادههای کلان برای پاسخ به وضعیتهای اضطراری، پیشگیری از جرم و ابتکارات شهر هوشمند استفاده میکنند.
نمونههایی از دادههای کلان چیست؟
دادههای کلان از منابع متعددی به دست میآیند، از جمله سیستمهای پردازش تراکنش، پایگاههای داده مشتری، اسناد، ایمیلها، سوابق پزشکی، گزارش های کلیک اینترنتی، برنامههای موبایل و شبکههای اجتماعی. همچنین شامل دادههای تولید شده توسط ماشین، مانند فایلهای لوگ شبکه و سرور و دادههای حسگر از ماشینهای تولیدی، تجهیزات صنعتی و دستگاههای اینترنت اشیا است.
علاوه بر دادههای موجود در سیستمهای داخلی، محیطهای دادههای کلان اغلب شامل دادههای خارجی در مورد مصرفکنندگان، بازارهای مالی، شرایط جوی و ترافیکی، اطلاعات جغرافیایی، تحقیقات علمی و غیره نیز میشوند. تصاویر، ویدیوها و فایلهای صوتی نیز اشکالی از دادههای کلان هستند و بسیاری از برنامههای دادههای کلان شامل دادههای جریانی هستند که به طور مداوم پردازش و جمعآوری میشوند.
بخش بندی دادههای کلان به سه مؤلفه V: حجم(Volume) ، تنوع(Variety) و سرعت(Velocity) 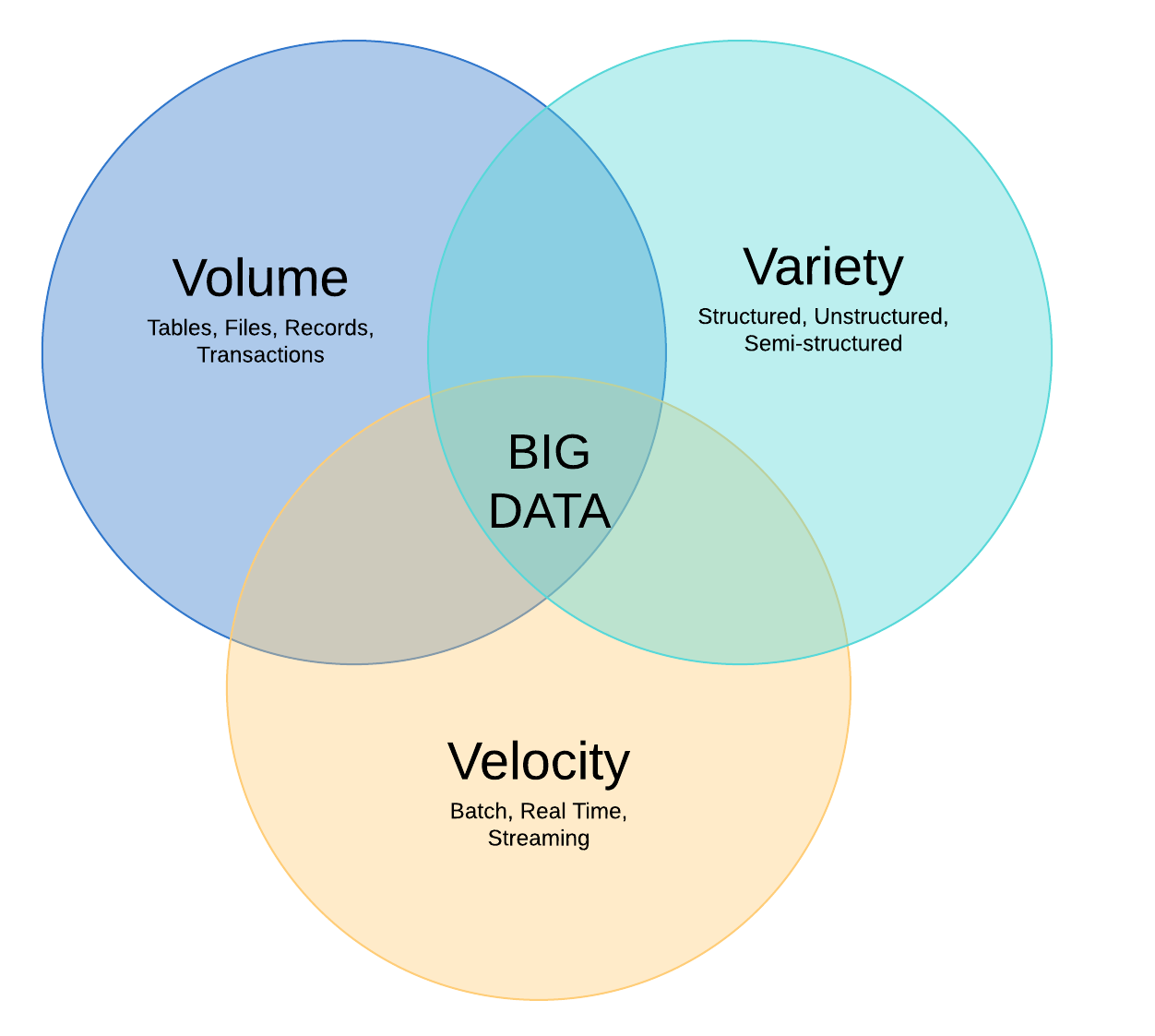
حجم، ویژگیای است که بیشترین استناد را در دادههای کلان دارد. یک محیط داده کلان نیازی به داشتن مقدار زیادی داده ندارد، اما بیشتر آنها به دلیل ماهیت دادههای جمعآوری و ذخیرهشده در آنها، حجم زیادی دارند. جریانهای کلیک، لاگهای سیستم و سیستمهای پردازش جریانی، از جمله منابعی هستند که معمولاً حجم عظیمی از داده را به طور مداوم تولید میکنند.
از نظر تنوع، دادههای کلان شامل چندین نوع داده است، از جمله موارد زیر:
دادههای ساختاری، مانند تراکنشها و سوابق مالی.
دادههای غیرساختاری، مانند متن، اسناد و فایلهای چندرسانهای.
دادههای نیمهساختاری، مانند لاگهای سرور وب و دادههای جریانی از حسگرها.
انواع مختلف دادهها باید در سیستمهای داده کلان ذخیره و مدیریت شوند. علاوه بر این، برنامههای کاربردی داده کلان معمولاً شامل مجموعههای داده متعددی هستند که نمیتوان آنها را به طور اولیه یکپارچه کرد.
سرعت به سرعتی اشاره دارد که دادهها تولید میشوند و باید پردازش و تحلیل شوند. در بسیاری از موارد، مجموعههای داده کلان بهطور واقعی یا نزدیک به واقعی به روز میشوند، به جای به روزرسانیهای روزانه، هفتگی یا ماهانه که در بسیاری از انبارهای داده سنتی انجام میشود. مدیریت سرعت دادهها به طور فزایندهای مهم تر میشود زیرا تحلیل داده کلان به یادگیری ماشین و هوش مصنوعی گسترش مییابد، جایی که فرآیندهای تحلیلی به طور خودکار الگوها را در دادهها پیدا کرده و از آنها برای تولید بینش استفاده میکنند.
ویژگیهای بیشتر دادههای کلان: صحت(Veracity) ، ارزش(Value) و تغییرپذیری(Variability) 
نگاهی فراتر از سه V اصلی، ویژگیهای دیگری نیز معمولاً با دادههای کلان همراه هستند. از جمله موارد زیر:
صحت
به درجه دقت در مجموعههای داده و میزان قابل اعتماد بودن آنها اشاره دارد. دادههای خام جمعآوری شده از منابع مختلف میتوانند باعث بروز مشکلات کیفیت داده شوند که شناسایی آنها ممکن است دشوار باشد. اگر این مشکلات از طریق فرآیندهای پاک سازی داده اصلاح نشوند، دادههای نادرست منجر به خطاهای تحلیلی میشوند که میتواند ارزش ابتکارات تحلیلهای تجاری را تضعیف کند. تیمهای مدیریت داده و تحلیلات نیز باید اطمینان حاصل کنند که دادههای دقیقی برای تولید نتایج معتبر در دسترس دارند.
ارزش
برخی از دانشمندان داده و مشاوران همچنین ارزش را به فهرست ویژگیهای دادههای کلان اضافه میکنند. تمام دادههای جمعآوری شده ارزش واقعی تجاری یا مزایای واقعی ندارند. به همین دلیل، سازمانها باید تأیید کنند که دادهها به مسائل تجاری مرتبط مربوط میشوند قبل از اینکه در پروژههای تحلیل دادههای کلان استفاده شوند.
تغییرپذیری
تغییرپذیری معمولاً به مجموعههای دادههای کلان مربوط میشود که ممکن است معانی متعدد داشته باشند یا در منابع داده جداگانه به شکل متفاوتی قالببندی شده باشند. این عوامل میتوانند مدیریت و تحلیل دادههای کلان را پیچیده کنند.
برخی افراد حتی Vهای بیشتری به دادههای کلان اطلاق میکنند؛ فهرستهای مختلفی ایجاد شده است که از هفت تا ۱۰ متغیر را شامل میشود.
چگونه دادههای کلان ذخیره و پردازش میشوند؟
دادههای کلان معمولاً در یک دریاچه داده (به فضایی اشاره دارد که در آن انواع مختلف دادهها، از جمله دادههای ساختاریافته و غیرساختاریافته، ذخیره میشوند. این مفهوم به دلیل قابلیتهای ذخیرهسازی و پردازش دادههای بزرگ در پلتفرمهای مختلف مانند هادوپ و خدمات ذخیرهسازی ابری اهمیت دارد) ذخیره میشوند. در حالی که انبارهای داده معمولاً بر روی پایگاههای داده رابطهای ساخته میشوند و فقط شامل دادههای ساختار یافته هستند، دریاچههای داده میتوانند از انواع مختلف دادهها پشتیبانی کنند و معمولاً بر اساس خوشههای هادوپ، خدمات ذخیرهسازی ابری، پایگاههای داده NoSQL یا سایر پلتفرمهای دادههای کلان ساخته میشوند.
پردازش دادههای کلان تقاضاهای سنگینی بر زیرساخت محاسباتی دارد. سیستمهای خوشه ای معمولاً قدرت محاسباتی مورد نیاز را ارائه میدهند. آنها جریان داده را مدیریت میکنند و از تکنولوژیهایی مانند هادوپ و موتور پردازش اسپارک برای توزیع بارهای پردازشی در میان صدها یا هزاران سرور معمولی استفاده میکنند.
دریافت چنین ظرفیتی برای پردازش به صورت مقرون به صرفه یک چالش است. به همین دلیل، Cloud به مکانی محبوب برای سیستمهای دادههای کلان تبدیل شده است. سازمانها میتوانند سیستمهای ابری خود را مستقر کنند یا از خدمات مدیریت شده دادههای کلان به عنوان سرویس از ارائه دهندگان ابری استفاده کنند. کاربران ابری می توانند تعداد مورد نیاز سرورها را به اندازه کافی برای اتمام پروژههای تحلیلی دادههای کلان افزایش دهند. کسب وکار تنها برای ذخیرهسازی داده و زمان محاسباتی که استفاده میکند، پرداخت میکند و نمونههای ابری میتوانند زمانی که نیاز نیستند خاموش شوند.
تحلیل دادههای کلان چگونه کار میکند؟
برای به دست آوردن نتایج معتبر و مرتبط از برنامههای تحلیل دادههای کلان، دانشمندان داده و سایر تحلیلگران داده باید درک دقیقی از دادههای موجود داشته باشند و بدانند که به دنبال چه چیزی هستند. این امر باعث میشود که آمادهسازی داده یک مرحله حیاتی در فرآیند تحلیل باشد. این مرحله شامل پروفایلسازی، پاکسازی، اعتبارسنجی و تبدیل مجموعههای داده است.
پس از جمعآوری و آمادهسازی دادهها برای تحلیل، میتوان از رشتههای مختلف علم داده و تحلیلهای پیشرفته برای اجرای برنامههای مختلف استفاده کرد، با استفاده از ابزارهایی که ویژگیها و قابلیتهای تحلیل دادههای کلان را فراهم میکنند. این رشتهها شامل یادگیری ماشین و زیرمجموعه یادگیری عمیق آن، مدل سازی پیشبینی، داده کاوی، تحلیل آماری، تحلیل جریانی و متنکاوی هستند.
استفاده از دادههای مشتری به عنوان مثال، شاخههای مختلف تحلیلی که میتوان با مجموعههای دادههای کلان انجام داد شامل موارد زیر است:
تحلیل مقایسهای
این تحلیل معیارهای رفتار مشتری و تعاملات مشتری در زمان واقعی را بررسی میکند تا محصولات، خدمات و برند یک شرکت را با رقبای آن مقایسه کند.
گوش دادن به رسانههای اجتماعی. این تحلیل میکند که مردم در رسانههای اجتماعی درباره یک کسبوکار یا محصول چه میگویند، که میتواند به شناسایی مشکلات بالقوه و هدفگذاری مخاطبان برای کمپینهای بازاریابی کمک کند.
تحلیل بازاریابی
این اطلاعاتی را ارائه میدهد که میتواند برای بهبود کمپینهای بازاریابی و پیشنهادات تبلیغاتی برای محصولات، خدمات و ابتکارات تجاری استفاده شود.
تحلیل احساسات
تمام دادههایی که در مورد تجربه مشتری جمعآوری میشود میتواند تحلیل شود تا نشان دهد که آنها چگونه به یک شرکت یا برند احساس میکنند، سطح رضایت مشتری، مشکلات بالقوه و چگونگی بهبود خدمات مشتری.
مزایای دادههای کلان
سازمانهایی که حجمهای بالای داده را به درستی استفاده و مدیریت میکنند، میتوانند از مزایای زیادی بهرهمند شوند، مانند موارد زیر:
تصمیمگیری بهبود یافته
یک سازمان میتواند بینشهای مهم، ریسکها، الگوها یا روندها را از دادههای کلان استخراج کند. مجموعههای بزرگ داده باید جامع باشند و قدرتمندترین اطلاعات را برای کمک به تصمیم گیریهای بهتر سازمان فراهم کنند. بینشهای دادههای کلان به رهبران کسب وکار اجازه میدهد تا به سرعت تصمیمات مبتنی بر داده اتخاذ کنند که بر سازمانهایشان تأثیر میگذارد.
بینشهای بهتر از مشتری و بازار
دادههای کلان که روندهای بازار و عادات مصرف کننده را پوشش میدهد، بینشهای مهمی را که یک سازمان برای برآورده کردن نیازهای مخاطبان هدف خود نیاز دارد ارائه میدهد. تصمیمات توسعه محصول به ویژه از این نوع بینش بهره مند می شوند.
صرفهجویی در هزینه
دادههای کلان میتوانند برای شناسایی راههایی که کسب وکارها میتوانند بهره وری عملیاتی خود را افزایش دهند استفاده شوند. به عنوان مثال، تحلیل دادههای کلان درباره استفاده از انرژی یک شرکت میتواند به آن کمک کند تا کارآمدتر شود.
تأثیر اجتماعی مثبت
دادههای کلان میتوانند برای شناسایی مشکلات قابل حل استفاده شوند، مانند بهبود خدمات بهداشتی یا مقابله با فقر در یک منطقه خاص.
چالشهای دادههای کلان
چالشهای مشترکی برای کارشناسان داده هنگام کار با دادههای کلان وجود دارد که شامل موارد زیر است:
طراحی معماری
نیازمندیهای مهارتی
هزینهها
مهاجرت( مهاجرت مجموعههای داده محلی و بارهای پردازشی به ابر میتواند یک فرآیند پیچیده باشد.)
قابلیت دسترسی
ادغام
کلیدهای یک استراتژی مؤثر دادههای کلان
توسعه یک استراتژی دادههای کلان نیازمند درک اهداف کسب وکار و دادههای موجود برای استفاده است، همچنین ارزیابی نیاز به دادههای اضافی برای کمک به دستیابی به اهداف. مراحل بعدی شامل موارد زیر است:
اولویت بندی موارد و کاربردهای مورد برنامه ریزی شده.
شناسایی سیستمها و ابزارهای جدیدی که مورد نیاز است.
ایجاد نقشه راه استقرار.
ارزیابی مهارتهای داخلی برای دیدن اینکه آیا به آموزش مجدد یا استخدام نیاز است.
برای اطمینان از اینکه مجموعههای دادههای کلان واضح، سازگار و به خوبی استفاده میشوند، یک برنامه حکمرانی داده و فرآیندهای مدیریت کیفیت داده نیز باید در اولویت باشد. روشهای دیگر برای مدیریت و تحلیل دادههای کلان شامل تمرکز بر نیازهای کسب وکار برای اطلاعات به جای فناوریهای موجود و استفاده از تجسم داده برای کمک به کشف و تحلیل دادهها است.
روشها و مقررات جمعآوری دادههای کلان
با افزایش جمعآوری و استفاده از دادههای کلان، پتانسیل سوءاستفاده از دادهها نیز افزایش یافته است. اعتراض عمومی در مورد نقض دادهها و سایر تخلفات حریم خصوصی شخصی باعث شد اتحادیه اروپا (EU) مقررات عمومی حفاظت از دادهها (GDPR) را تصویب کند، قانونی در زمینه حریم خصوصی دادهها که در ماه مه ۲۰۱۸ به اجرا درآمد.
GDPR انواع دادههایی را که سازمانها میتوانند جمع آوری کنند محدود کرده و نیاز به رضایت قبلی از افراد یا رعایت سایر دلایل مشخص برای جمعآوری دادههای شخصی را الزامی میکند. این قانون همچنین شامل حق فراموشی است که به ساکنان اتحادیه اروپا اجازه میدهد از شرکتها بخواهند دادههایشان را حذف کنند.
در حالی که قانونی مشابه در ایالات متحده وجود ندارد، قانون حریم خصوصی مصرف کننده کالیفرنیا (CCPA) هدفش این است که به ساکنان کالیفرنیا کنترل بیشتری بر جمعآوری و استفاده از اطلاعات شخصیشان توسط شرکتهایی که در این ایالت فعالیت میکنند بدهد. CCPA در سال ۲۰۱۸ به قانون تبدیل شد و از اول ژانویه ۲۰۲۰ به اجرا درآمد. این لایحه اولین مورد از نوع خود در ایالات متحده بود. تا سال ۲۰۲۳، ۱۲ ایالت دیگر نیز قوانین جامع مشابهی برای حفاظت از دادهها تصویب کردهاند.
دیگر تلاشهای جاری برای جلوگیری از سوءاستفاده از دادههای کلان توسط فناوریهایی مانند هوش مصنوعی و یادگیری ماشین شامل قانون هوش مصنوعی اتحادیه اروپا است که پارلمان اروپا در مارس ۲۰۲۴ آن را تصویب کرد. این یک چارچوب نظارتی جامع برای استفاده از هوش مصنوعی است که به توسعه دهندگان هوش مصنوعی و شرکتهایی که فناوری هوش مصنوعی را به کار میبرند، راهنماییهایی بر اساس سطح خطر مدلهای هوش مصنوعی ارائه میدهد.
برای اطمینان از رعایت قوانین مربوط به دادههای کلان، کسب وکارها باید به دقت فرآیند جمعآوری آن را مدیریت کنند. باید کنترلهایی برای شناسایی دادههای تحت تنظیم و جلوگیری از دسترسی کارکنان غیرمجاز و دیگر افراد به آنها ایجاد شود.
جنبه انسانی مدیریت و تحلیل دادههای کلان
در نهایت، ارزش و مزایای تجاری ابتکارات دادههای کلان به کارمندانی که مسئول مدیریت و تحلیل دادهها هستند بستگی دارد. برخی از ابزارهای دادههای کلان به کاربرانی که کمتر فنی هستند اجازه می دهند تا برنامههای تحلیل پیش بینی را اجرا کنند یا به کسب وکارها کمک کنند زیرساخت مناسبی برای پروژههای دادههای کلان ایجاد کنند، همچنین نیاز به دانش سخت افزاری و نرم افزاری توزیع شده را به حداقل میرسانند.
دادههای کلان را میتوان با دادههای کوچک مقایسه کرد، اصطلاحی که گاهی برای توصیف مجموعههای دادهای که می توان به راحتی برای Self-service BI استفاده کرد، به کار میرود. یک قاعده معمولاً نقل قول شده این است: "دادههای کلان برای ماشینها؛ دادههای کوچک برای انسانها."
آینده دادههای کلان
تعدادی از فناوریهای نوظهور احتمالاً بر نحوه جمعآوری و استفاده از دادههای کلان تأثیر خواهند گذاشت. روندهای فناوری زیر بیشترین تأثیر را بر آینده دادههای کلان خواهند داشت:
تحلیل هوش مصنوعی و یادگیری ماشین: مجموعههای داده بزرگ تر میشوند و بنابراین تحلیل آنها توسط چشمهای انسانی کمتر کارآمد است. الگوریتمهای هوش مصنوعی و یادگیری ماشین در حال تبدیل شدن به کلید انجام تحلیلهای مقیاس بزرگ و حتی وظایف مقدماتی، مانند پاک سازی و پیش پردازش مجموعههای داده هستند. ابزارهای یادگیری ماشین خودکار احتمالاً در این زمینه مفید خواهند بود.
ذخیرهسازی بهبود یافته با ظرفیت افزایش یافته: قابلیتهای ذخیرهسازی ابری به طور مداوم در حال بهبود است. دریاچهها و انبارهای داده، که می توانند هم به صورت محلی و هم در ابر باشند، گزینههای جذابی برای ذخیرهسازی دادههای کلان هستند.
تأکید بر حاکمیت: حاکمیت داده و مقررات به تدریج جامع تر و رایج تر خواهند شد، زیرا مقدار دادههای مورد استفاده افزایش می یابد و نیاز به تلاش بیشتری برای حفاظت و تنظیم آن وجود خواهد داشت.
محاسبات کوانتومی: اگرچه کمتر از هوش مصنوعی شناخته شده است، محاسبات کوانتومی نیز میتواند تحلیلهای دادههای کلان را با قدرت پردازش بهبود یافته تسریع کند. این فناوری در مراحل اولیه توسعه است و تنها برای شرکتهای بزرگ با دسترسی به منابع گسترده در دسترس است.
منبع: https://www.techtarget.com/searchdatamanagement/definition/big-data
مدیر وبلاگ: هلیا خدابخش
دیتاتو مدیریت دادههای کسبوکار را هوشمندانه و بصورت خودکار انجام میدهد، با دیتاتو در ارتباط باشید.